
AI algorithms have recently gained a lot of recognition for their remarkable capacity to replicate the human learning process. Just as humans observe and interpret visual information to understand the world, AI algorithms analyze images pixel by pixel, extracting features and patterns to comprehend their contents. In order to have a successful AI model, a large amount of data is required. This is especially true in the realm of AI in medical imaging due to the large variation in the appearance of suspicious lesions found in each image. However, a larger dataset does not automatically mean the machine learning models trained from them will perform better. After training thousands of models, we’ve come to recognize the immense complexities inherent in model training. This article explores some of those complexities that extend beyond sheer data quantity.
Data Diversity
One of the fundamental challenges in leveraging AI for medical imaging stems from the variations between the training dataset which AI learns from, and the real-world data. Various factors can affect data quality and their applicability in real-world scenarios. Let’s examine CXR images from two datasets.
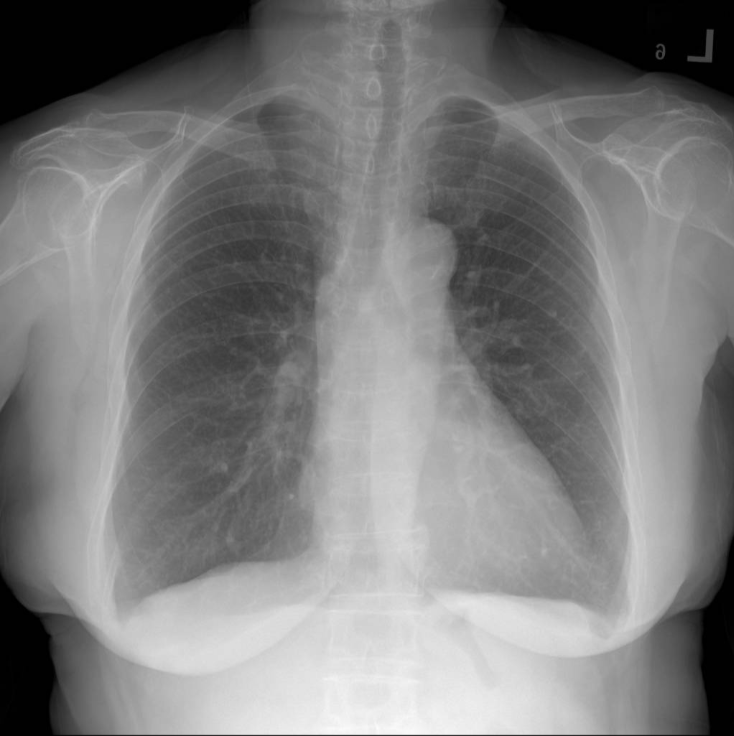
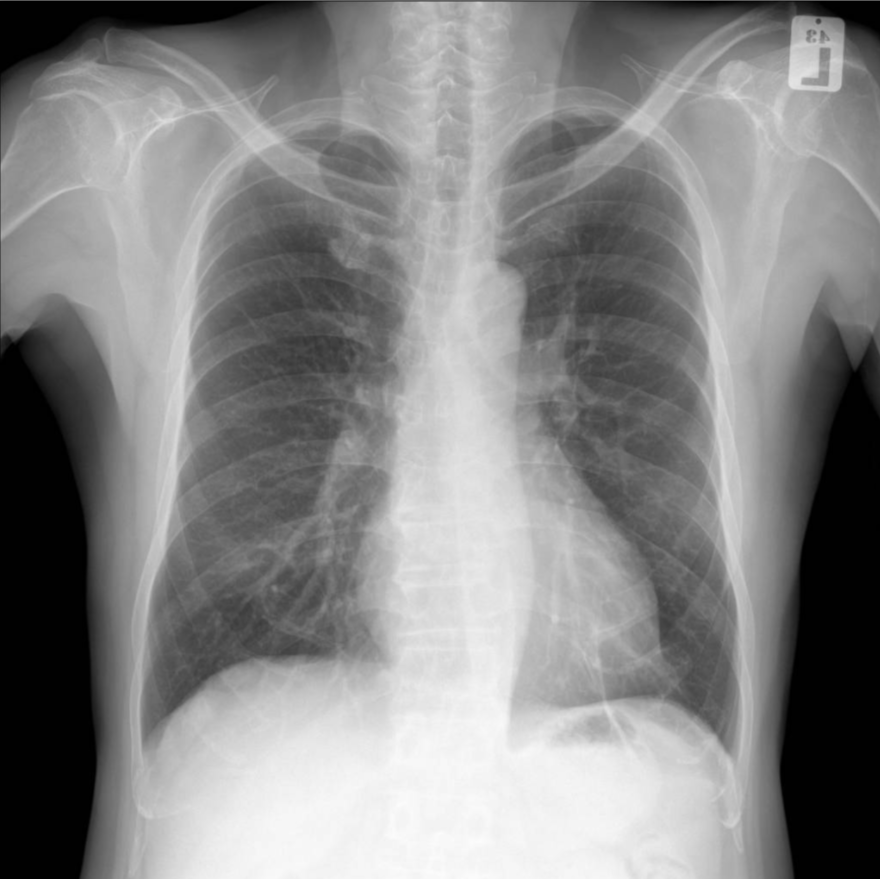
These are images from dataset A. They are called PA view CXR images, representing the standard view captured by X-ray machines. This view is practiced in most diagnosis tasks, including health checkups and disease screenings at hospitals.
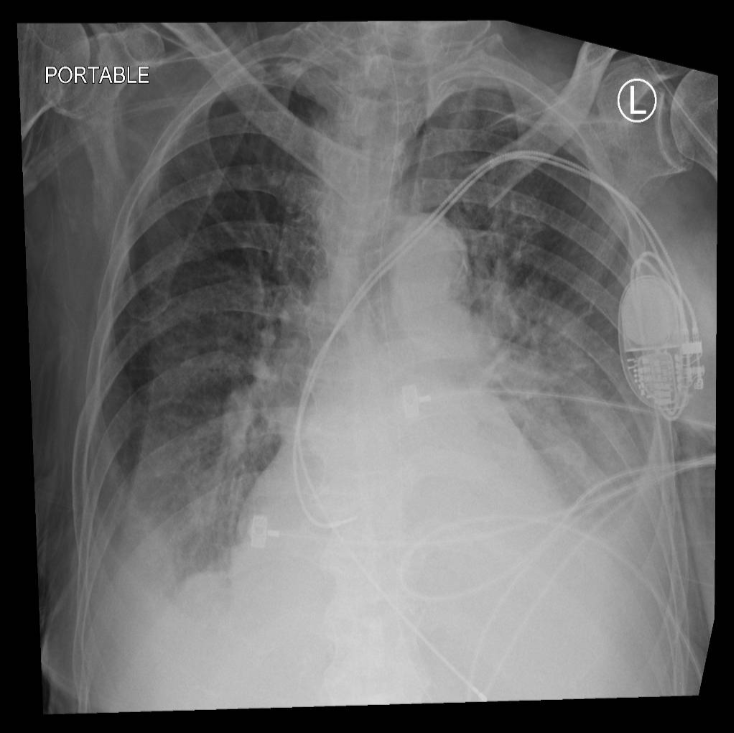
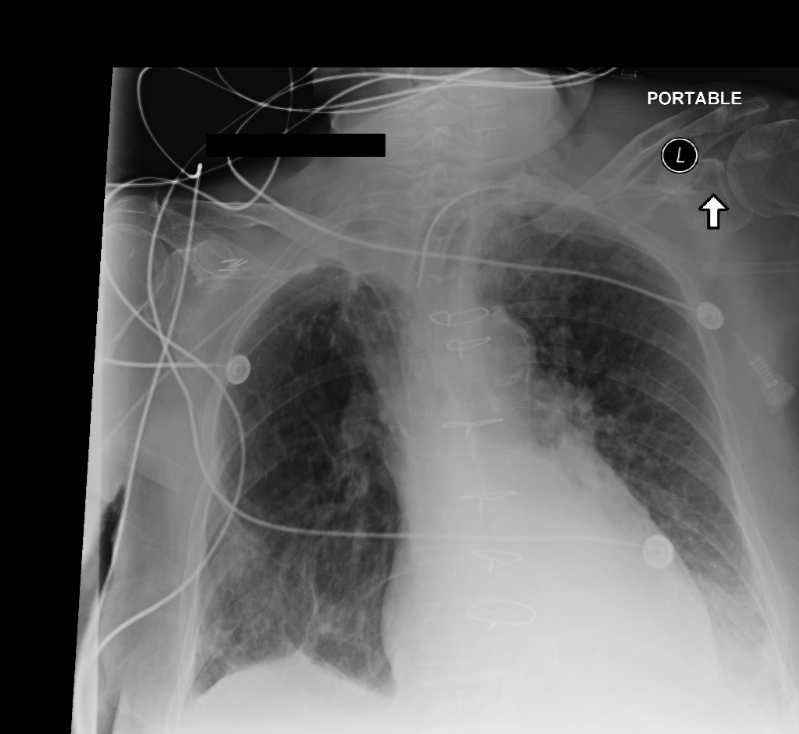
On the other hand, these are images from dataset B, depicting a portable view obtained from a portable CXR device, which typically offers radiographs with lower quality than those captured by the standard fixed X-ray machines. The images are usually rotated, filled with black borders, and contain numerous support devices such as tubes or pacemakers. Portable views are commonly utilized in mobile chest x-ray cars or emergency rooms.
Combining these images for training presents inherent challenges and biases to the model. Therefore, careful consideration is essential when selecting data sources, determining which types of data to include or exclude, as they significantly influence the success of the trained model and help to avoid biases and inaccuracies in the AI’s predictions. Furthermore, using unlabeled data can also be considered to further improve the AI’s ability to handle different image types and scenarios effectively.
Data Quality
Given the impracticality of humans verifying every data point in a large dataset, they are typically subject to automatic processing at various stages of the process. Throughout the process, images unsuitable for our training objectives might be included. In the case of training our CXR models, sometimes we find images with poor exposure or, more critically, images of other body parts mistakenly included. Such occurrences can originate from errors during data storage, leading to incorrect queries by the system. To address these issues, various techniques like outlier detection are employed to filter out these erroneous data points. While some data may escape automatic identification, we strive to filter out the majority of such instances (or at least we hope to do so!)
Label Accuracy
The core, the crux, and the heart of our machine learning model: the label. The labels consist of “positive” or “negative” tags affixed to each image, indicating the presence or absence of diseases within the image. Similar to guiding a child, accurate labels are imperative for AI models to learn and make good decisions.
In large chest X-ray datasets, the labels are derived from radiologist reports using algorithms called chest X-ray labelers. Most of the current labelers are either created with rule-based approaches or learned from labels extracted by them. Despite their effectiveness in analyzing grammar and sentence structures to extract findings from radiologist reports, rule-based approaches, which form the basis for most label generation, are susceptible to exceptions found within medical reports.
To identify erroneous labels, we employ active learning techniques, which identify and rectify noisy samples where labels may be incorrect. Let’s see an example.
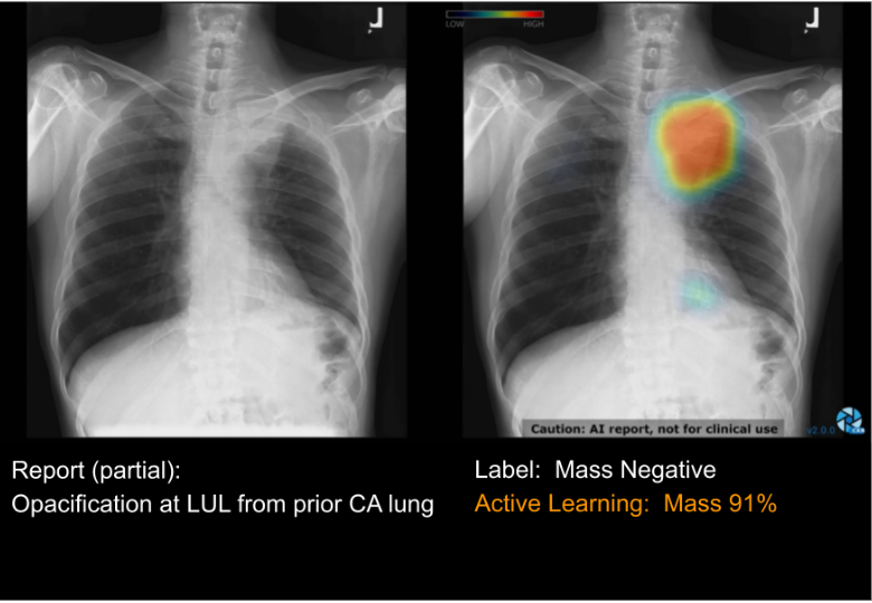
Consider a raw chest X-ray image (Left) displaying an unusual opacity in the upper-left region of the lung. (The left side is indicated by the letter L found on top of the film.) We call this lung mass. Therefore the label “Mass” should be present in the image. However, the radiologist report identifies this lesion as the opacification from prior CA (cancer), indicating that the cancer from the previous film has solidified. If another radiologist were to review the case, there would be no issue, as they would promptly recognize the presence of the mass and relate it to the opacification keyword. However, the rule-based labeler erroneously assigned a “negative” label to the “Mass” category. Indeed, we could incorporate the “opacification” keyword into our labeling rules for the “Mass” category. However, there may be instances where this keyword is not indicative of the masses, complicating the need for meticulous rule verification, thus rendering the process very complex.
Therefore, after extensive correction of labeler errors, we performed an active learning approach for this task. The outcome, displayed on the right side, illustrates the result of our active learning approach, which effectively identifies and highlights noisy regions within the image. This iterative process aids in swiftly correcting labeling errors, with early iterations achieving an accuracy of approximately 70-80% in identifying noise.
Together with double-checking the labels, working closely with radiologists is also the key to making sure labels are correct and helps improve AI performance.
This wraps up the discussion on the crucial role of data in influencing model performance. Training the model and validating its outcomes is also equally intricate and will be covered in another blog post. Developing AI for medical imaging is like putting together a complex puzzle. We continuously refine our model while maintaining clear communication with our users regarding its capabilities and limitations. By doing so, we aim to consistently maximize the benefits to Thailand’s healthcare system. We hope our insights into medical AI have sparked your interest in this field, or at least provided some insights applicable to your endeavors.


")